|
I am a research scientist at Google Brain, where I work on deep reinforcement learning and meta-learning. Previously, I completed my PhD at Berkeley AI Research Lab (BAIR) where I was advised by Sergey Levine. I studied deep reinforcement learning and robotics. I completed my B.S. at Caltech where I worked with Yisong Yue and Pietro Perona on computer vision. Email / Google Scholar / LinkedIn / Github / CV |

|
|
My long-term goal is help build general AI and use that to accelerate research in other fields. I'm interested in combining deep learning with reinforcement learning in order to solve complex decision making problems. Areas of interest include computer vision, representation learning, and natural language processing all at the intersection with control and reinforcement learning in order to build complex autonomous agents that can understand the world, learn from previous behavior, and operate intelligently with humans. I'm currently interested in studying the emergence of intelligent behavior in complex environments with simple unsupervised learning objectives. |
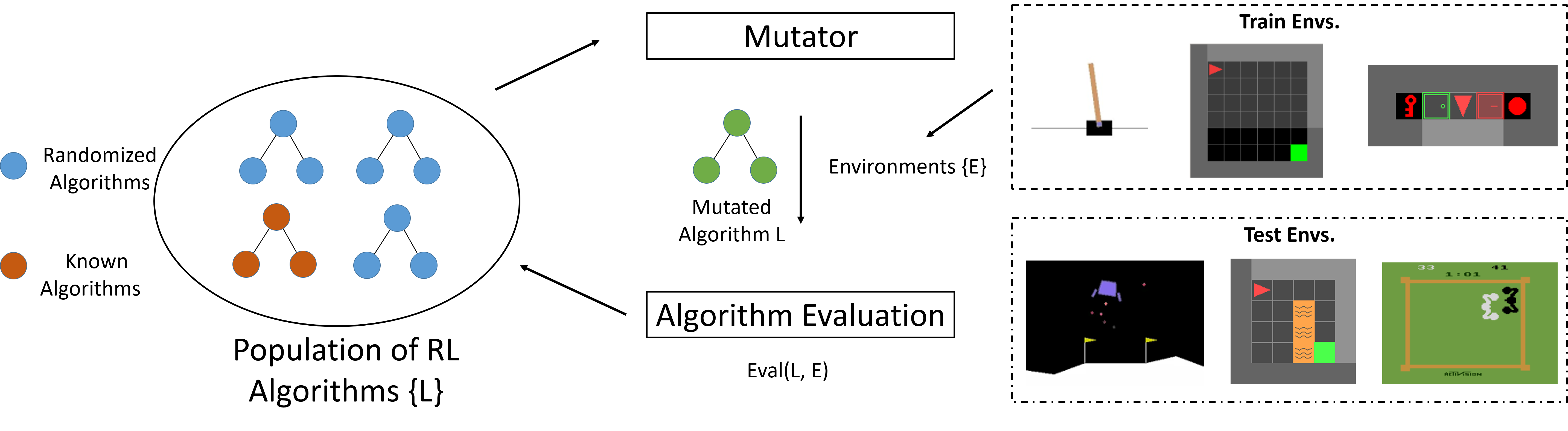
|
John D. Co-Reyes, Yingjie Miao, Daiyi Peng, Esteban Real, Sergey Levine, Quoc V. Le, Honglak Lee, Aleksandra Faust International Conference on Learning Representations, 2021 Oral Presentation, 1.8% acceptance rate. Mentioned in Google AI Year in Review, Analytics India Magazine project page / code / algorithms / poster / blog post We propose a method for meta-learning reinforcement learning algorithms by searching over the space of computational graphs which compute the loss function for a value-based model-free RL agent to optimize. The learned algorithms are domain-agnostic and can generalize to new environments not seen during training. Our method can both learn from scratch and bootstrap off known existing algorithms, like DQN, enabling interpretable modifications which improve performance. Learning from scratch on simple classical control and gridworld tasks, our method rediscovers the temporal-difference (TD) algorithm. Bootstrapped from DQN, we highlight two learned algorithms which obtain good generalization performance over other classical control tasks, gridworld type tasks, and Atari games. The analysis of the learned algorithm behavior shows resemblance to recently proposed RL algorithms that address overestimation in value-based methods. |
|
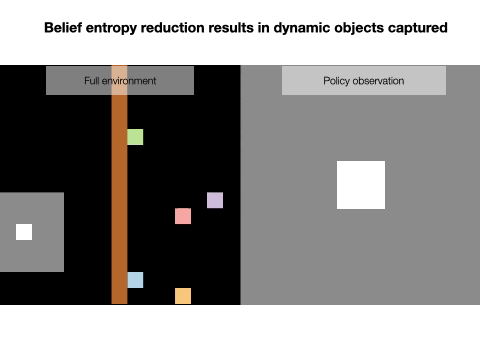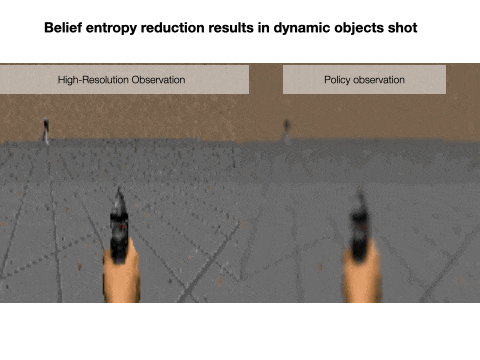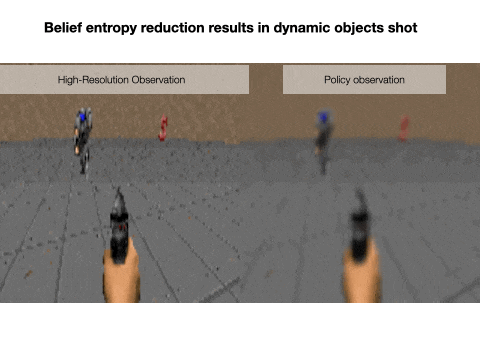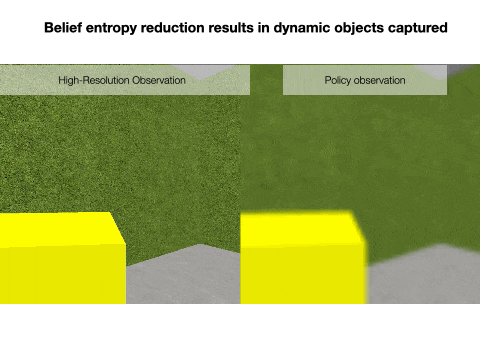
Nick Rhinehart, Jenny Wang, Glen Berseth, John D. Co-Reyes, Danijar Hafner, Chelsea Finn, Sergey Levine NeurIPS, 2021 project page Humans and animals explore their environment and acquire useful skills even in the absence of clear goals, exhibiting intrinsic motivation. The study of intrinsic motivation in artificial agents is concerned with the following question: what is a good general-purpose objective for an agent? We study this question in dynamic partially-observed environments, and argue that a compact and general learning objective is to minimize the entropy of the agent's state visitation estimated using a latent state-space model. This objective induces an agent to both gather information about its environment, corresponding to reducing uncertainty, and to gain control over its environment, corresponding to reducing the unpredictability of future world states. We instantiate this approach as a deep reinforcement learning agent equipped with a deep variational Bayes filter. We find that our agent learns to discover, represent, and exercise control of dynamic objects in a variety of partially-observed environments sensed with visual observations without extrinsic reward. |
|
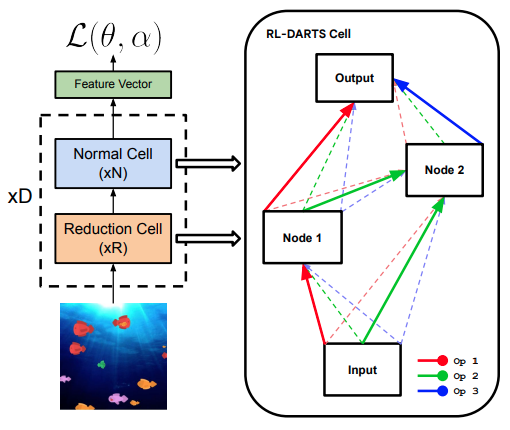
Yingjie Miao, Xingyou Song, Daiyi Peng, Summer Yue, John D. Co-Reyes, Eugene Brevdo, Aleksandra Faust arXiv, 2021 Recently, Differentiable Architecture Search (DARTS) has become one of the most popular Neural Architecture Search (NAS) methods successfully applied in supervised learning (SL). However, its applications in other domains, in particular for reinforcement learning (RL), has seldom been studied. This is due in part to RL possessing a significantly different optimization paradigm than SL, especially with regards to the notion of replay data, which is continually generated via inference in RL. In this paper, we introduce RL-DARTS, one of the first applications of end-to-end DARTS in RL to search for convolutional cells, applied to the challenging, infinitely procedurally generated Procgen benchmark. We demonstrate that the benefits of DARTS become amplified when applied to RL, namely search efficiency in terms of time and compute, as well as simplicity in integration with complex preexisting RL code via simply replacing the image encoder with a DARTS supernet, compatible with both off-policy and on-policy RL algorithms. At the same time however, we provide one of the first extensive studies of DARTS outside of the standard fixed dataset setting in SL via RL-DARTS. We show that throughout training, the supernet gradually learns better cells, leading to alternative architectures which can be highly competitive against manually designed policies, but also verify previous design choices for RL policies. |
|
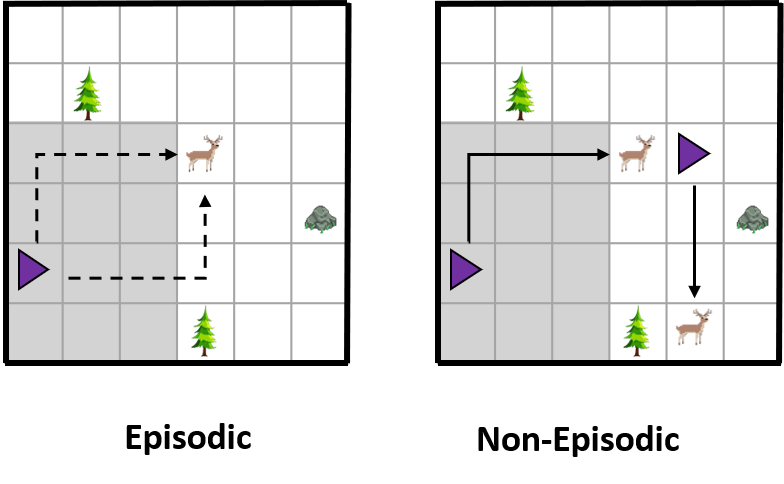
John D. Co-Reyes*, Suvansh Sanjeev*, Glen Berseth, Abhishek Gupta, Sergey Levine NeurIPS Deep RL Workshop, 2019 project page / code Much of the current work on reinforcement learning studies episodic settings, where the agent is reset between trials to an initial state distribution, often with well-shaped reward functions. Non-episodic settings, where the agent must learn through continuous interaction with the world without resets, and where the agent receives only delayed and sparse reward signals, is substantially more difficult, but arguably more realistic considering real-world environments do not present the learner with a convenient "reset mechanism" and easy reward shaping. In this paper, instead of studying algorithmic improvements that can address such non-episodic and sparse reward settings, we instead study the kinds of environment properties that can make learning under such conditions easier. Understanding how properties of the environment impact the performance of reinforcement learning agents can help us to structure our tasks in ways that make learning tractable. We first discuss what we term "environment shaping" -- modifications to the environment that provide an alternative to reward shaping, and may be easier to implement. We then discuss an even simpler property that we refer to as "dynamism," which describes the degree to which the environment changes independent of the agent's actions and can be measured by environment transition entropy. Surprisingly, we find that even this property can substantially alleviate the challenges associated with non-episodic RL in sparse reward settings. We provide an empirical evaluation on a set of new tasks focused on non-episodic learning with sparse rewards. Through this study, we hope to shift the focus of the community towards analyzing how properties of the environment can affect learning and the ultimate type of behavior that is learned via RL. |

|
Rishi Veerapaneni*, John D. Co-Reyes*, Michael Chang*, Michael Janner, Chelsea Finn, Jiajun Wu, Joshua B. Tenenbaum, Sergey Levine Conference on Robot Learning, 2019 project page / code / poster This paper tests the hypothesis that modeling a scene in terms of entities and their local interactions, as opposed to modeling the scene globally, provides a significant benefit in generalizing to physical tasks in a combinatorial space the learner has not encountered before. We present object-centric perception, prediction, and planning (OP3), which to the best of our knowledge is the first fully probabilistic entity-centric dynamic latent variable framework for model-based reinforcement learning that acquires entity representations from raw visual observations without supervision and uses them to predict and plan. OP3 enforces entity-abstraction -- symmetric processing of each entity representation with the same locally-scoped function -- which enables it to scale to model different numbers and configurations of objects from those in training. Our approach to solving the key technical challenge of grounding these entity representations to actual objects in the environment is to frame this variable binding problem as an inference problem, and we develop an interactive inference algorithm that uses temporal continuity and interactive feedback to bind information about object properties to the entity variables. On block-stacking tasks, OP3 generalizes to novel block configurations and more objects than observed during training, outperforming an oracle model that assumes access to object supervision and achieving two to three times better accuracy than a state-of-the-art video prediction model that does not exhibit entity abstraction. |
|
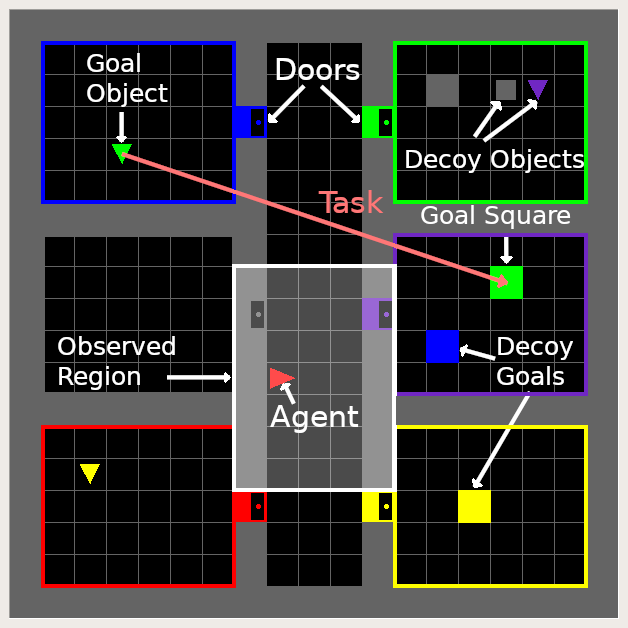
John D. Co-Reyes, Abhishek Gupta, Suvansh Sanjeev, Nick Altieri, Jacob Andreas, Pieter Abbeel Sergey Levine International Conference on Learning Representations, 2019 Best Paper at Meta-Learning Workshop at NeurIPS, 2018 project page / poster / workshop slides / code Behavioral skills or policies for autonomous agents are conventionally learned from reward functions, via reinforcement learning, or from demonstrations, via imitation learning. However, both modes of task specification have their disadvantages: reward functions require manual engineering, while demonstrations require a human expert to be able to actually perform the task in order to generate the demonstration. Instruction following from natural language instructions provides an appealing alternative: in the same way that we can specify goals to other humans simply by speaking or writing, we would like to be able to specify tasks for our machines. However, a single instruction may be insufficient to fully communicate our intent or, even if it is, may be insufficient for an autonomous agent to actually understand how to perform the desired task. In this work, we propose an interactive formulation of the task specification problem, where iterative language corrections are provided to an autonomous agent, guiding it in acquiring the desired skill. Our proposed language-guided policy learning algorithm can integrate an instruction and a sequence of corrections to acquire new skills very quickly. In our experiments, we show that this method can enable a policy to follow instructions and corrections for simulated navigation and manipulation tasks, substantially outperforming direct, non-interactive instruction following. |
|
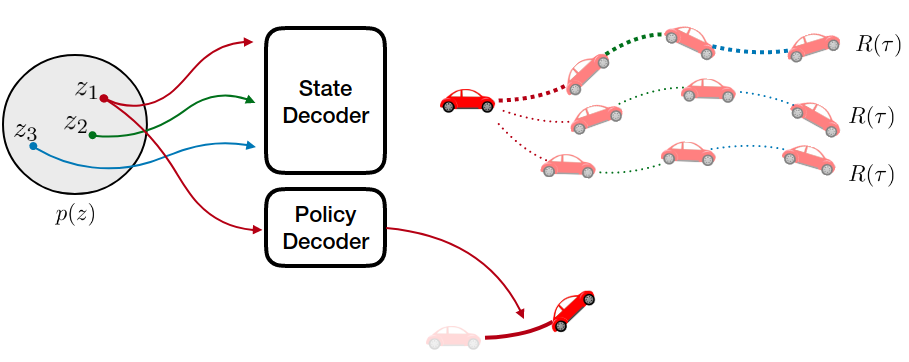
John D. Co-Reyes*, YuXuan Liu*, Abhishek Gupta*, Benjamin Eysenbach, Pieter Abbeel Sergey Levine International Conference on Machine Learning, 2018 project page / code / poster / video In this work, we take a representation learning perspective on hierarchical reinforcement learning, where the problem of learning lower layers in a hierarchy is transformed into the problem of learning trajectory-level generative models. We show that we can learn continuous latent representations of trajectories, which are effective in solving temporally extended and multi-stage problems. Our proposed model, SeCTAR, draws inspiration from variational autoencoders, and learns latent representations of trajectories. A key component of this method is to learn both a latent-conditioned policy and a latent-conditioned model which are consistent with each other. Given the same latent, the policy generates a trajectory which should match the trajectory predicted by the model. This model provides a built-in prediction mechanism, by predicting the outcome of closed loop policy behavior. We propose a novel algorithm for performing hierarchical RL with this model, combining model-based planning in the learned latent space with an unsupervised exploration objective. We show that our model is effective at reasoning over long horizons with sparse rewards for several simulated tasks, outperforming standard reinforcement learning methods and prior methods for hierarchical reasoning, model-based planning, and exploration. |
|
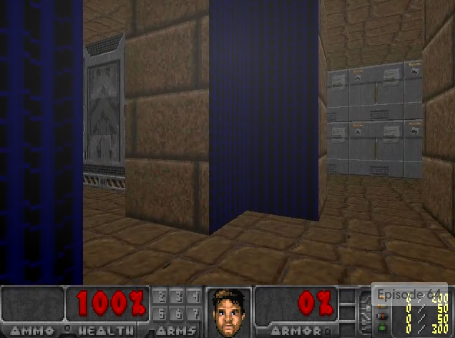
Justin Fu*, John D. Co-Reyes*, Sergey Levine Advances in Neural Information Processing Systems (NIPS), 2017 Spotlight Presentation. 4.69% acceptance rate (152/3240) project page / code / poster / conference slides Deep reinforcement learning algorithms have been shown to learn complex tasks using highly general policy classes. However, sparse reward problems remain a significant challenge. Exploration methods based on novelty detection have been particularly successful in such settings but typically require generative or predictive models of the observations, which can be difficult to train when the observations are very high-dimensional and complex, as in the case of raw images. We propose a novelty detection algorithm for exploration that is based entirely on discriminatively trained exemplar models, where classifiers are trained to discriminate each visited state against all others. Intuitively, novel states are easier to distinguish against other states seen during training. We show that this kind of discriminative modeling corresponds to implicit density estimation, and that it can be combined with count-based exploration to produce competitive results on a range of popular benchmark tasks, including state-of-the-art results on challenging egocentric observations in the vizDoom benchmark. |
|
|

|
|